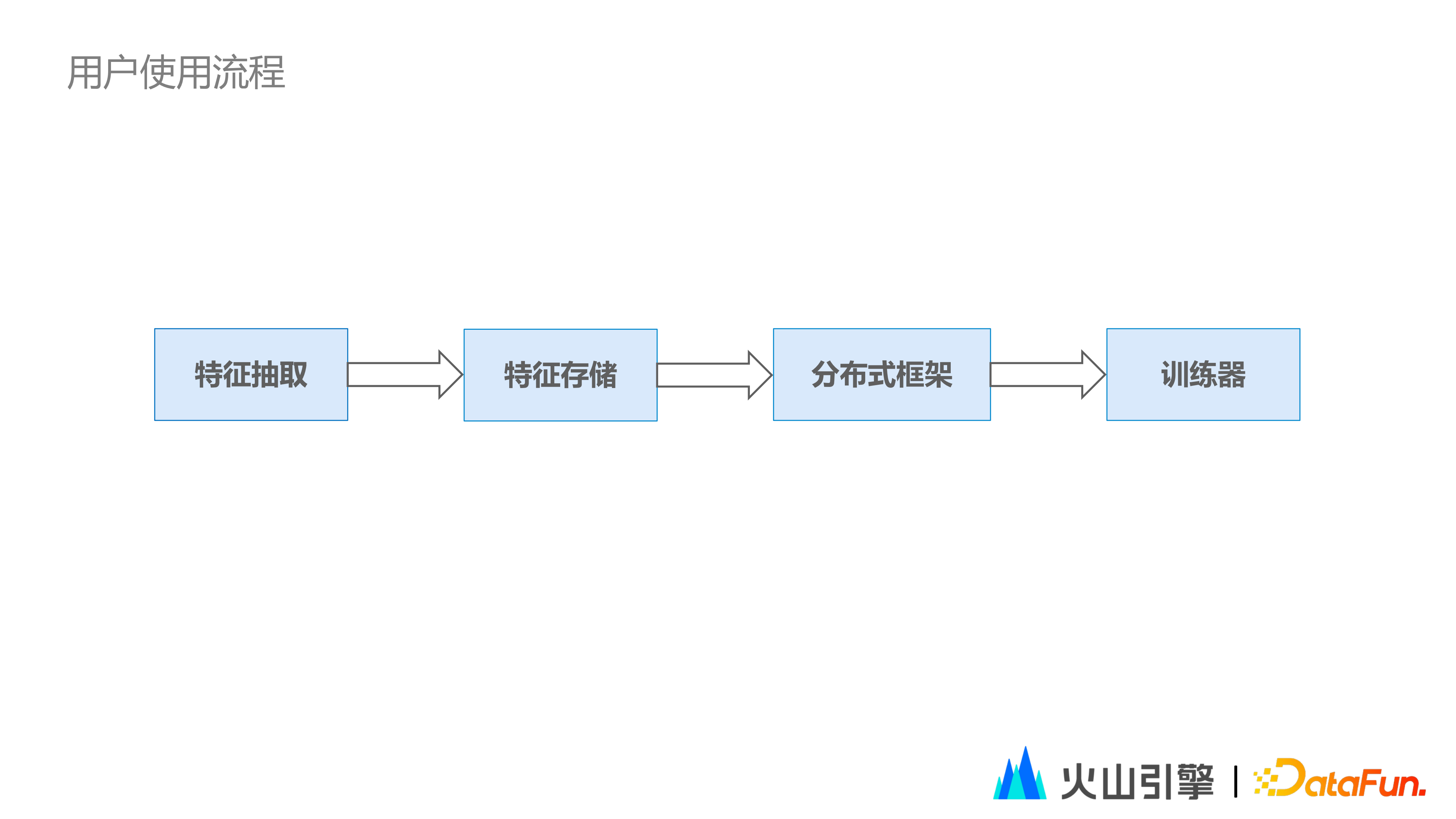
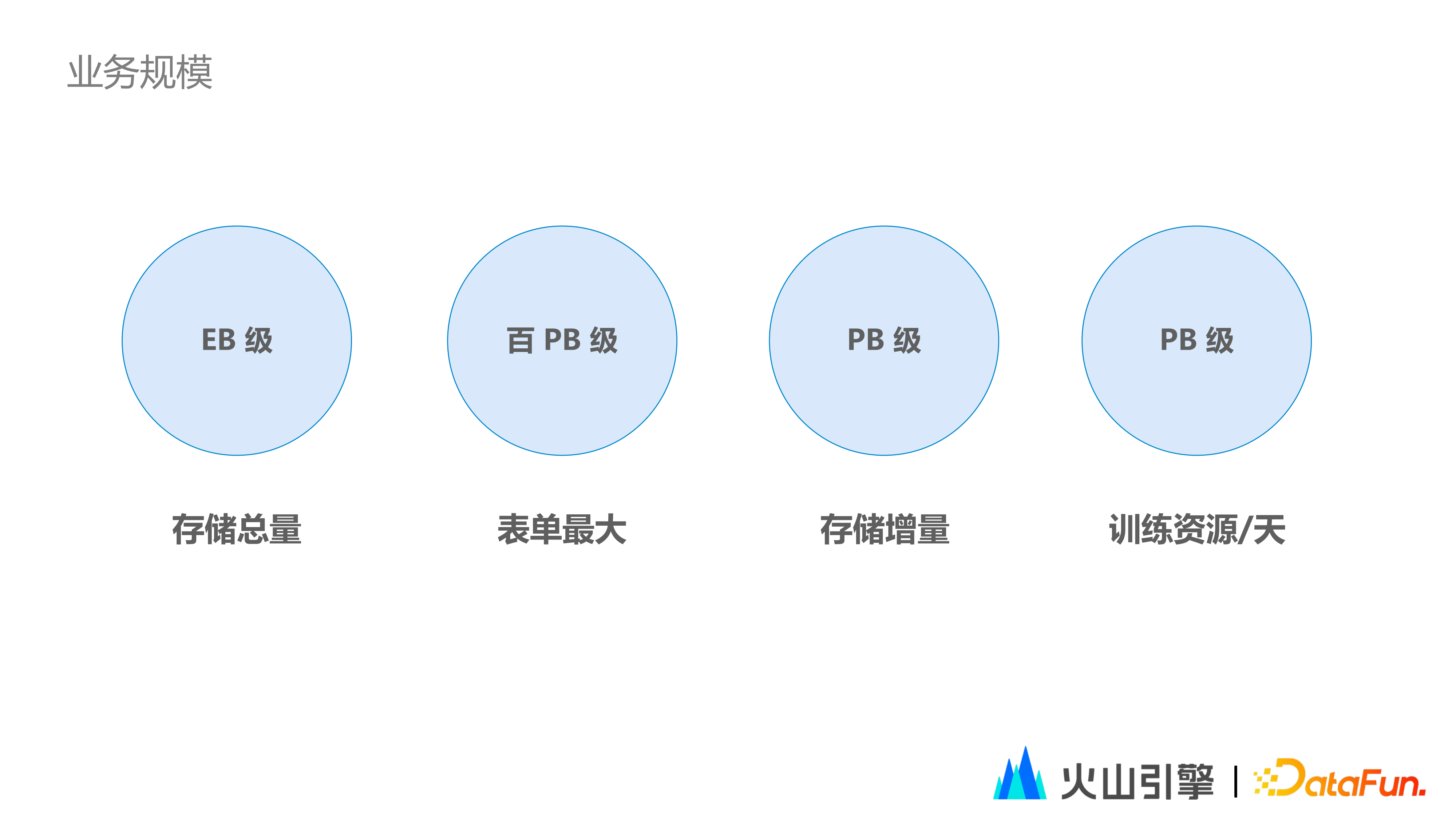
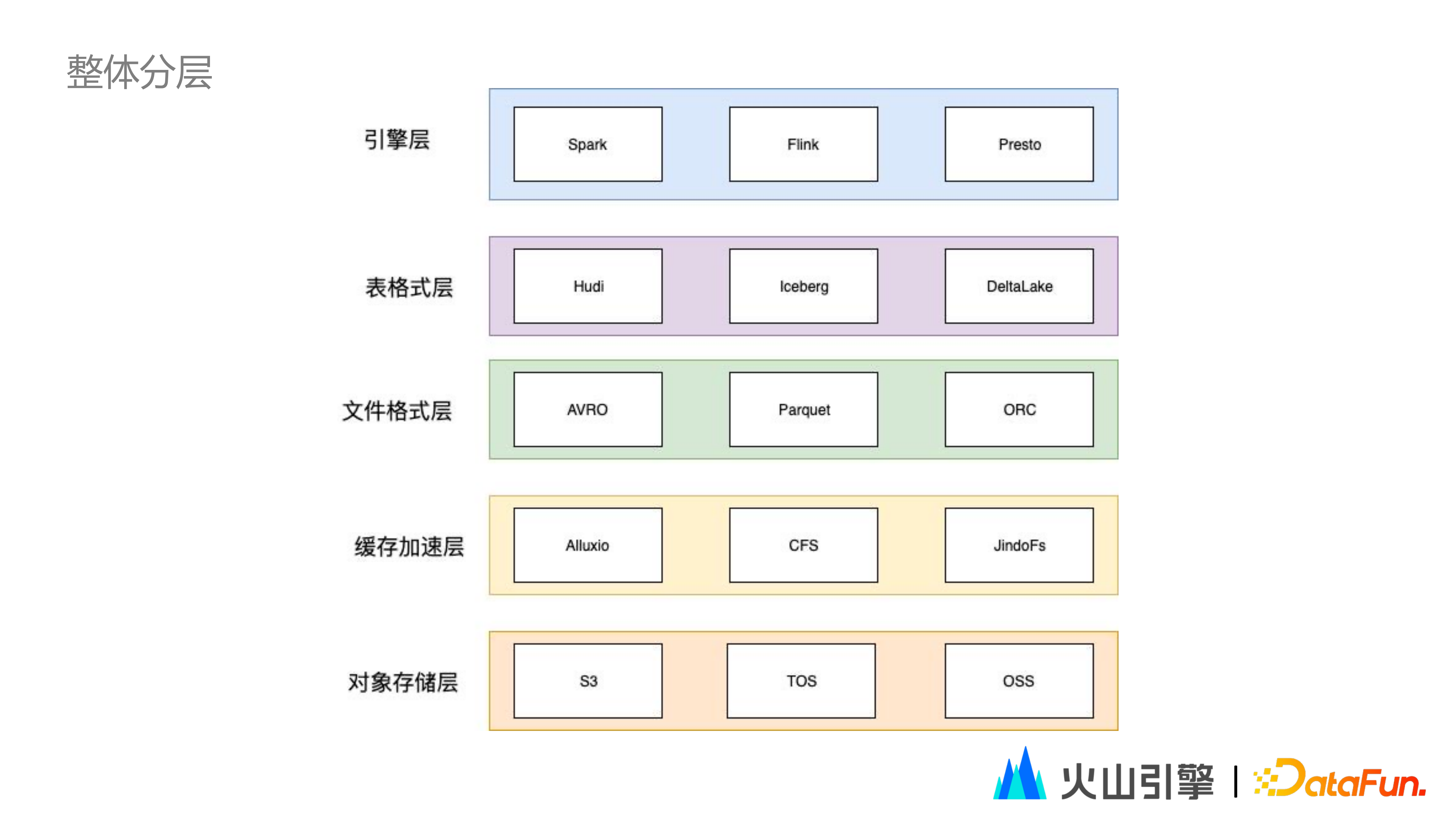
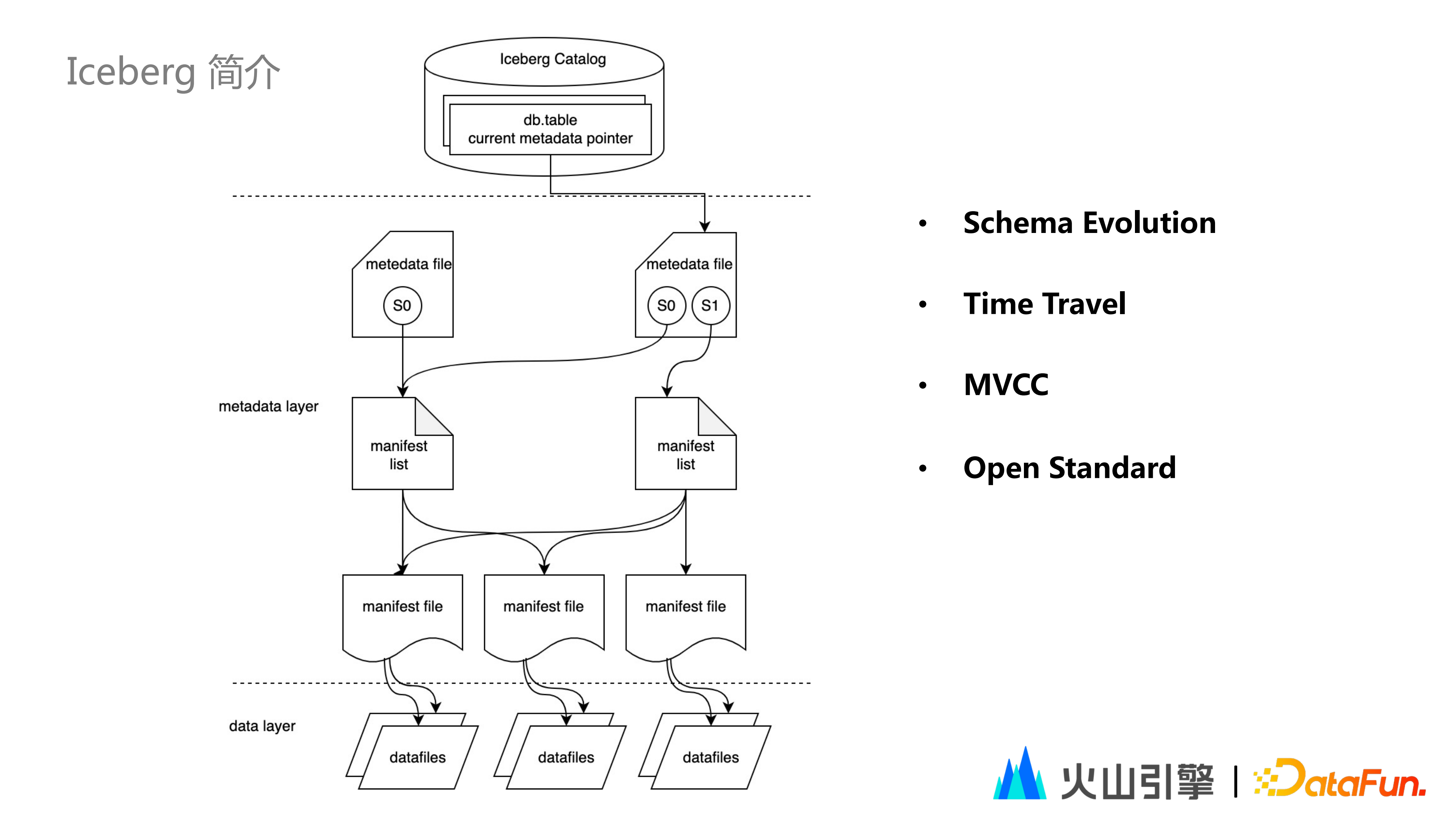
2023-05-15 12:28:38 3557 举报

版权声明:本文内容由Webmeng实名注册用户自发贡献,版权归原作者所有,搜寻云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《搜寻云开发者社区用户服务协议》和《Webmeng开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
评论
 数字人是推动元宇宙到来的重要推手
在大淘宝技术,前端、后端、算法工程师的日常是什么样的?
库克:苹果的下一站将是印度
星链卫星互联网下月结束测试
苹果推送iOS 15 正式版更新内容通知
数字人是推动元宇宙到来的重要推手
在大淘宝技术,前端、后端、算法工程师的日常是什么样的?
库克:苹果的下一站将是印度
星链卫星互联网下月结束测试
苹果推送iOS 15 正式版更新内容通知